

RAID5を構成していたSynology NASのストレージがRead Errorを出していたな、と思い出し、HDDを入れ替えてリビルドしていたらRAID再構築中にHDDがクラッシュしてリビルド停止、そのままディスクアレイごとクラッシュして復旧できなくなりました。
本記事は、その状態からデータを退避させるまでの時系列順にした忘備録です。
目次
NASクラッシュまでのバックグラウンド

今回紹介するNASは、当サイトでも何回かにわたって使用方法や拡張方法などを紹介しているSynologyのDS916+です。
クラッシュ直前にはDX513も追加してストレージ拡張を行っており、3TB×7台によるRAID5でディスクアレイを構成していました。
使用しているHDDはNAS運用を見越したWestern DigitalのWD Redでクラッシュするまでの稼働時間は10,000h程。DS916+は風通しを良くしたクローゼット内に安置しており、HDDの動作温度は最大でも50℃程。NASの中ではDockerバックアップなどが常に色々走っている状態でした。
2018-12-20 不良セクタの修正ログが発生
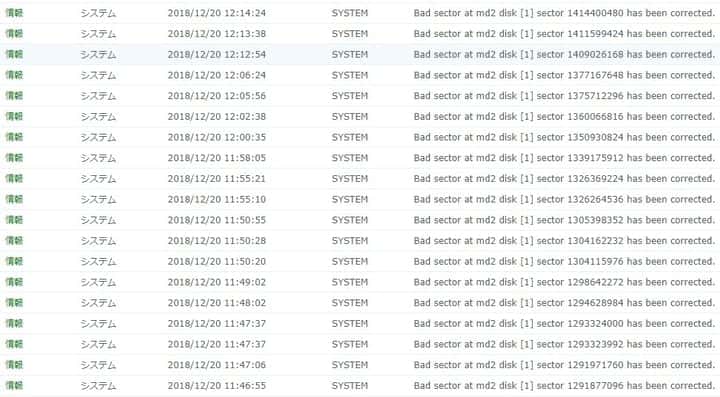
12月の末にRAID5を構成しているHDDの1つから「不良セクタが発生したが問題を修正」の通知が発生。
ログには問題が発生したセクタまで記録されていたものの、S.M.A.R.T上では特に問題も無く、実際の使用にも問題がなかったため、リビルド用のHDDを注文して使用を続けていました。
RAID5ならHDDが1台クラッシュしても問題ないので、余裕のある時間を見計らってリビルドする予定でした。
2019-01-03 21:29 リビルド開始
年も明けて落ち着いたころ、購入しておいたHDDに換装しようとHDDの入れ替えを開始します。
今回、HDD交換のリビルドは2回目なので、1回目の時と同じようにHDDを交換したのちリビルドを開始して復旧するまでの10時間を待つだけのはずでした
2019-01-03 21:37 ディスクアレイがクラッシュ
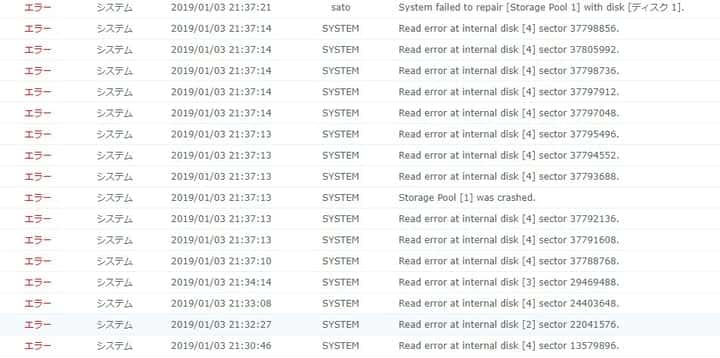
問題が発生したのはリビルドを開始してから僅か8分後、3台のディスクからリードエラーが発生し、その内のDisk[4]が連続してリードエラーを多発した直後にディスクがクラッシュしたと警告通知。
RAID5のリビルド中にHDDが1台クラッシュしたことによってRAID5の冗長性が失われ、リビルドが停止しました。
リビルド中のHDDを元に戻して、リビルドをクラッシュしたDisk[4]に対してやり直せば現状維持はできるのではないか?と考え、NASを一旦シャットダウンしてHDD構成を元に戻しても、既にリビルドを実行した場所に対して、元のHDDを正しく認識することもありませんでした。
ただ、再起動後には何故かクラッシュしたDisk[4]の状態が回復しており「このままもう一度リビルドできそう」ともう一度リビルドを開始するも、さっきと同じようにDisk[4]がクラッシュ。どうやらHDDは本当に破損しているでした。
ここからが問題です、本当に重要なデータのみ他のメディアにバックアップしているものの、出来る事なら可能な限りデータを吸い出したいところです。
調べてみたところ不良セクターが原因によるRAID5ディスクアレイ破損の場合、対応方法は3つあります。
1つ目が、デュプリケーターを使ってHDDをクローンして再ビルド
2つ目が、HDD Regenerator等の不良セクタ修復ツールを使用してから再度リビルド
3つ目が、復旧業者の使用、だそうです。
2019-01-03 22:00頃 読み取り可能な状態に気付く
幸運なことに、複数台のHDDのクラッシュによってRAID5ボリュームの復旧はできなくなりましたが、アクセス自体は可能な状態になっていました。
RAID5は複数台のHDDがクラッシュしても即読み取れなくなるわけではなく、HDD自体が動作していればデータを抜き取ることが可能なようです。
今回のトラブルは、RAID5のリビルド中にほかのHDDでも不良セクタを検出してしまったためにリビルドが止まってしまったものでした。
2019-01-03 22:30~現在 データ退避開始
別の用途で使用する予定の大容量HDDがあったので、クラッシュしたRAID5ボリュームのデータを全て退避することにしました。
SMBによるネットワークアクセスも可能な状態なので、そのままネットワーク越しにデータの退避を始めまます。データ読み取り中にも不良セクタはポツポツ発生しており、そのセクタのデータは読み込み不可となるため、いくつかのデータは破損していました
危惧していた通り、データ退避を始めた数時間のうちにさらにHDDの不良セクタ検出が発生しました。それでも尚、読み込みは可能なのでやはり「不良セクタでのクラッシュでも読める部分は読み込める」仕様になっているのかもしれません。九死に一生を得た感じです。
現在までに退避したデータは約4割ほど、この記事が公開が公開される日にはすべてのデータ退避が完了している頃です。
結局、クラッシュの原因は何だったのか
結局、今回の不良セクタ多発によるリビルド失敗&クラッシュの裏では下のような流れがあったものと推定されます。
- Disk[1]で不良セクタ検知(ほぼ同時に[2][3][4]でも不良セクタが多発していたが検知せず)
- リビルド中に初めて他ドライブの不良セクタ領域に入り込んでNASがクラッシュと判定
- リビルド停止、2台以上のHDD欠損によってディスクアレイクラッシュ
リビルド中にHDDがクラッシュするという話はよく聞きますが、ほとんどの場合、リビルド中に新しく遭遇した不良セクタが原因と考えられます。
RAID5に関しては、2台以上HDDがクラッシュによってリビルドは不可能になりましたが、読み込みは可能だったので、クラッシュに遭遇してもまずは落ち着いて現状を観察するのが重要だと思います。
WD Redにした割には10,000h程度で立て続けに不良セクタが発生したのは運用的な問題点があったのかもしれませんし、RAIDを構成する上で避けねばならない「同一ロットのHDDを購入しない」の鉄則を破って適当にHDDを購入していたのでHDDが壊れる時期が近くなってしまったのかもしれません。
NASの管理方法については、3Dプリンタのや定置型工具の近くにNASを設置していたのでそういう微振動も影響したのかなと推測されます、過去に見た動画では、ディスクアレイに大声で叫ぶとディスクのレイテンシが悪くなるという検証動画があるくらいなので、その辺の影響も考えればきりがありません。
DX513のストレージ拡張時には問題がなかったため、少なくともストレージ拡張時点まではHDDは健康だったものと推定されます。結局、HDDが複数台壊れた原因は分からずじまいではありますが、NASの設置場所などは少し考え直さないといけないかもしれません。











